
L'epistemia è un concetto che nasce per descrivere come gli esseri umani costruiscono, percepiscono e credono di possedere conoscenza. Ha a che fare con convinzioni, verità soggettive, illusioni cognitive. Applicarla a un sistema che lavora per probabilità, statistica e inferenza numerica non è un'operazione sensata: è antropomorfismo mascherato da filosofia. Sarebbe come accusare un motore di "credere" che la strada sia in salita.
Non so quando abbiamo deciso che fosse una buona idea spiegare le macchine usando categorie nate per consolare gli esseri umani. Forse è successo nel momento esatto in cui l'intelligenza artificiale ha iniziato a fare paura, e la paura, si sa, chiama sempre la filosofia, anche quando servirebbe un manuale di ingegneria.
Si parla molto a sproposito di "illusioni", di "conoscenza apparente", di macchine che sembrano sapere ma in realtà non sanno. E' una narrativa completamente fuori bersaglio.
Perchè una macchina non sembra nulla. Non crede, non afferma, non inganna. Calcola. E quando sbaglia, lo fa in modo brutalmente onesto: seguendo le regole che le abbiamo dato, o (molto più spesso) quelle che non le abbiamo dato affatto.
Io non ho mai avuto paura delle macchine. Ho sempre avuto paura degli esseri umani che preferiscono usare parole sbagliate invece di assumersi la responsabilità delle scelte tecniche. L’idea che l’intelligenza artificiale “allucini” è diventata un rifugio narrativo perfetto: ci consente di non parlare di pipeline, di architettura, di limiti, di controllo. È molto più rassicurante accusare la macchina di illusione che ammettere di averla lasciata senza confini.
Il futuro dell’intelligenza artificiale generativa è dietro l'angolo, e la linea che separa un beneficio collettivo da una catastrofe senza precedenti è sottilissima. Ma non passa dove molti credono. Non passa dalla coscienza della macchina, è dalla sua presunta volontà. Passa da come costruiamo i confini, dai limiti che imponiamo, dalla logica che decidiamo di rispettare o di ignorare.
Questo non è il racconto di un'IA che diventa troppo intelligente. È il racconto di un'umanità che rischia di diventare troppo pigra per restare responsabile. Io parto da qui: dall’idea che le allucinazioni non siano un destino, ma un sintomo. E che la singolarità, ormai in dirittura di arrivo, non sarà un'esplosione improvvisa. Sarà una scelta. Tecnica. Politica. Umana.
Come detto una macchina non sa, non crede, non finge. Non può avere illusioni di conoscenza, perchè non possiede alcuna conoscenza nel senso umano del termine. Possiede modelli matematici, distribuzioni di probabilità, vincoli logici. Quando produce un errore, non sta ingannando nessuno: sta seguendo fedelmente una struttura progettata male o lasciata incompleta. Parlare di epistemia in questo contesto non chiarisce il problema, lo oscura.
Quello che segue non è una sintesi accademica nè una rielaborazione di teorie esistenti. Le architetture, i concetti di pipeline vincolata, lago di informazioni, mini-singolarità controllata e le riflessioni sul rapporto tra intelligenza artificiale, metodo e responsabilità umana sono frutto della mia inventiva personale, maturata come programmatore e designer di sistemi di IA applicata.
Non propongo dogmi nè verità definitive, ma un modello progettuale coerente, costruito sull'esperienza diretta, sulla sperimentazione e su una visione precisa di come l'IA generativa dovrebbe essere progettata per evitare errori sistemici e disinformazione.
Chi legge è invitato a seguire il ragionamento, non ad accettarlo per autorità.
Tenetevi forte.
Non perchè la macchina stia per svegliarsi.
Ma perchè, forse, è arrivato il momento che lo facciamo noi.
Epistemia: perchè è il termine sbagliato per parlare di intelligenza artificiale
Il primo errore, rilevato in apertura, quello che contamina tutto il dibattito, nasce dall'uso disinvolto della parola epistemia. E' una parola potente, antica, affascinante. Ed è anche totalmente fuori contesto quando viene applicata all’intelligenza artificiale generativa. L'epistemia riguarda il modo in cui l’essere umano costruisce la conoscenza, il rapporto tra verità, credenza e percezione. Presuppone un soggetto che crede di sapere. Una macchina non crede nulla. Non ha coscienza, non ha intenzionalità, non ha illusione. Applicarle categorie epistemologiche umane è un errore concettuale, non una raffinata provocazione filosofica.
Un sistema di IA generativa lavora su spazi probabilistici, statistica ad alta dimensionalità, inferenza numerica. Quando produce un risultato errato, non sta manifestando un’illusione di conoscenza: sta semplicemente seguendo un percorso matematico compatibile con i vincoli (o con l'assenza di vincoli) che gli sono stati imposti. Parlare di epistemia in questo contesto equivale a dire che una calcolatrice "crede" che due più due faccia quattro. È un antropomorfismo comodo ma fuorviante.
Il termine allucinazione, così come viene usato oggi, nasce dallo stesso equivoco. Le allucinazioni non sono un fenomeno cognitivo della macchina, ma un sintomo architetturale. Sono il risultato diretto di modelli generalisti lasciati liberi di inferire senza una base informativa delimitata, senza una pipeline logica che filtri, confronti e verifichi. Attribuire tutto questo a una presunta epistemia artificiale serve solo a spostare l'attenzione dal progetto allo strumento, dalla responsabilità umana alla macchina.
Io parto da una posizione netta: se una risposta è sbagliata, la colpa non è dell'IA, ma di come è stata progettata e utilizzata.
L'epistemia non c’entra. C’entrano i vincoli, le fonti, la logica di validazione, l'assenza o la presenza di una pipeline strutturata. Finchè continueremo a usare parole sbagliate per descrivere sistemi matematici, continueremo anche a porci le domande sbagliate. E il futuro dell'IA generativa non ha bisogno di nuove etichette filosofiche: ha bisogno di architettura, metodo e limiti chiari.
Le allucinazioni non sono un bug, ma una scelta architetturale
Le cosiddette allucinazioni dell’intelligenza artificiale generativa vengono spesso descritte come un difetto inevitabile, quasi fisiologico. Un limite intrinseco della tecnologia, qualcosa con cui "imparare a convivere". Questa narrazione è tanto comoda quanto falsa.
Le allucinazioni non sono un bug misterioso che emerge spontaneamente dal modello: sono la conseguenza diretta di scelte architetturali precise, spesso fatte per mancanza di visione.
Un modello generativo lasciato libero di operare su un dominio informativo indistinto è, per definizione, costretto a riempire i vuoti. Quando mancano vincoli, fonti delimitate e meccanismi di verifica, l'inferenza probabilistica continua comunque il suo percorso. Non si ferma, non segnala incertezza, non "sa di non sapere" (per dirlo alla Socrate). Produce l'output più plausibile dato il contesto. Questo comportamento non è un errore cognitivo: è matematica applicata in assenza di confini.
Le allucinazioni emergono quindi quando si pretende che un sistema generalista funzioni come un sistema affidabile. È una pretesa irrazionale. Un modello generalista non è progettato per essere coerente, ma per essere flessibile. Non è progettato per verificare, ma per generare. Se gli si chiede di fare entrambe le cose senza una struttura intermedia, il risultato è inevitabile: risposte formalmente corrette, semanticamente plausibili e fattualmente errate.
Qui sta il punto che molti evitano di affrontare: l'allucinazione è una scelta di progetto, non una proprietà ontologica dell'IA. Nasce quando si rinuncia deliberatamente a costruire una pipeline logica che separi la generazione dalla validazione. Nasce quando si preferisce un unico modello onnivoro a una costellazione di modelli specialistici, ciascuno vincolato a un ambito informativo preciso. Nasce quando l’obiettivo non è l'affidabilità, ma la sensazione di intelligenza.
Io considero questa impostazione non solo tecnicamente debole, ma concettualmente irresponsabile. Non perchè la macchina "sbagli" per definizione, ma perchè la si mette deliberatamente nelle condizioni di farlo. Parlare di allucinazioni come di un destino inevitabile serve solo a giustificare l'assenza di metodo. Ma quando l'architettura è sbagliata, non è l'output a essere inaffidabile, ma l'intero sistema.
Perchè il modello generalista è un errore strutturale
Il modello generalista viene spesso presentato come il punto di arrivo naturale dell'intelligenza artificiale: un sistema che sa tutto, risponde a tutto, si adatta a tutto. E' una visione seducente, quasi mitologica, ma tecnicamente fragile. Un modello che non ha un dominio chiaro non può avere coerenza, perchè la coerenza nasce sempre da un perimetro definito. Senza confini, l'inferenza non diventa più potente: diventa indistinta.
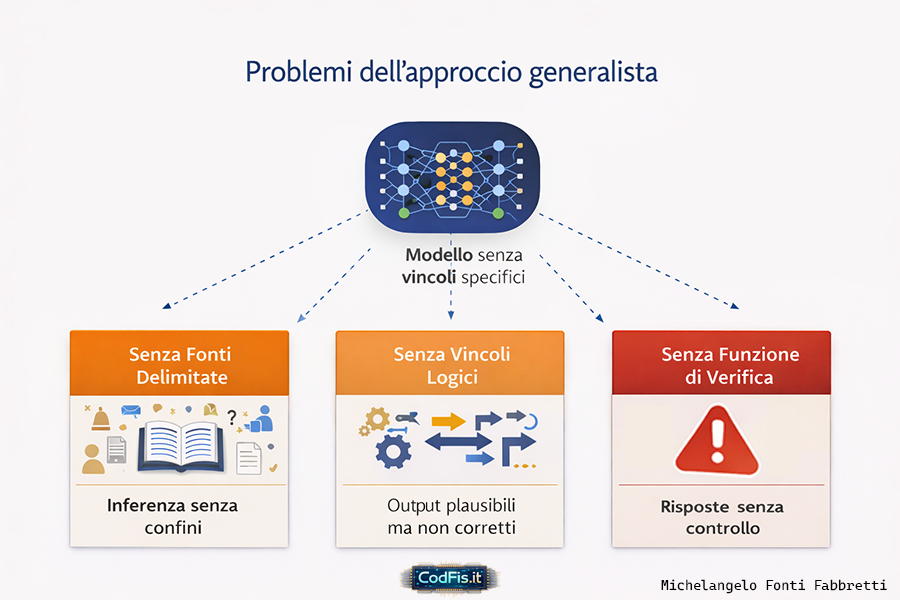
Un sistema generalista è costretto a trattare ogni richiesta come equivalente, anche quando non lo è. Non distingue ciò che richiede rigore da ciò che ammette approssimazione. Non separa il contesto narrativo da quello tecnico, l'opinione dall'informazione verificabile. In assenza di una struttura che discrimini, tutto viene appiattito sul piano della plausibilità.
Il modello non ha modo di sapere quando deve fermarsi. Un sistema progettato per generare non può, da solo, decidere di validare. Pretendere che un unico modello faccia entrambe le cose significa confondere flessibilità con affidabilità. Sono due obiettivi diversi, spesso incompatibili, che richiedono livelli distinti e ruoli separati.
Io considero il modello generalista una scorciatoia concettuale. Funziona bene nelle demo, nei contesti informali, nella conversazione libera. Ma diventa inadeguato non appena entra in gioco la responsabilità: scuola, diritto, sanità, informazione, decisioni pubbliche. In questi ambiti non serve un sistema che sa dire qualcosa. Serve un sistema che sa dire solo ciò che può essere sostenuto, verificato e contestualizzato.
E' per questo che la direzione non è un modello sempre più grande, ma modelli più piccoli e numerosi, ciascuno vincolato a un ambito informativo preciso, coordinati da una logica superiore. Il generalismo non è il futuro dell'IA affidabile: è il suo limite attuale. E finchè continueremo a inseguirlo come ideale, continueremo anche a produrre sistemi che sembrano intelligenti, ma non sono progettati per essere affidabili.
La pipeline logica come separazione tra generazione e verifica
Il punto di svolta, quello che rende possibile un'IA generativa senza allucinazioni, non è il modello in sè, ma ciò che gli sta intorno. La mia idea di pipeline logica nasce proprio da questa esigenza: separare in modo netto ciò che genera da ciò che verifica. Se due funzioni restano fuse nello stesso livello, l'errore non è solo possibile, è statisticamente inevitabile.
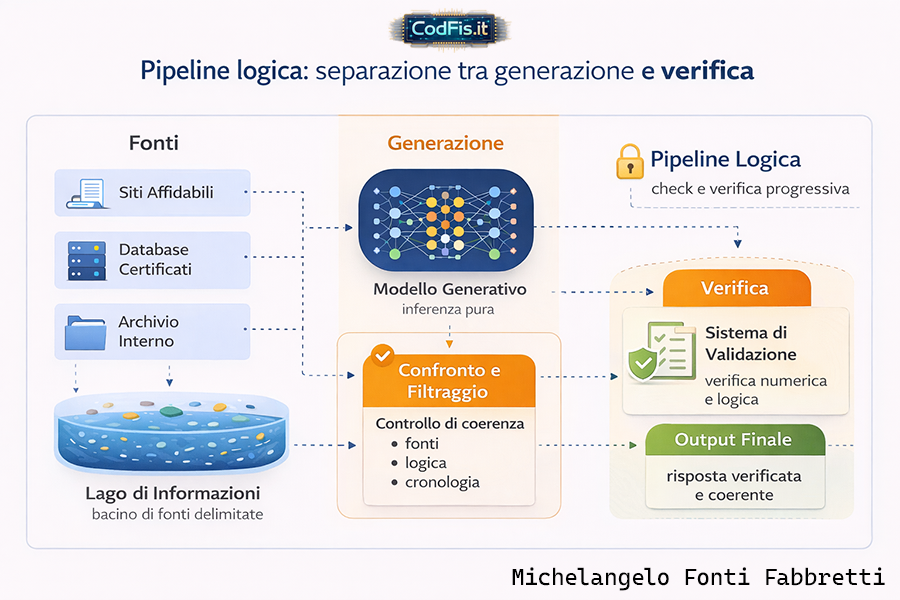
Un modello generativo fa una cosa sola, e la fa bene: produce inferenze plausibili. Non è progettato per decidere aprioristicamente se un'informazione sia vera, coerente o compatibile con un contesto già validato. Pretendere che lo faccia significa attribuirgli un ruolo che non gli compete.
La pipeline logica serve a rimettere ordine: prima si genera, poi si filtra, poi si confronta, infine si valida. Ogni fase ha un compito preciso, e nessuna invade il campo dell'altra. E' una dicotomia figlia di logica e determinismo, alla stregua di come funzionano i neuroni del nostro cervello.
In questo schema, l'errore non viene "corretto" a posteriori, ma intercettato a monte. Le fonti vengono selezionate, confrontate tra loro, sottoposte a controlli di coerenza. Le informazioni che non rispettano gli assunti di base non vengono propagate, ma isolate. Non perchè siano "sbagliate" in senso assoluto, semplicemente non sono compatibili con il perimetro logico definito. E' una differenza cruciale, che trasforma l'inferenza da atto creativo incontrollato a processo progettato.
La pipeline non è una censura e non è un freno all'intelligenza del sistema. E', al contrario, la condizione che rende l'intelligenza utilizzabile. Senza pipeline (o filiera logica del ragionamento), ogni risposta è un atto unico, scollegato, non confrontabile. Con una pipeline, ogni risposta diventa parte di un sistema coerente, verificabile nel tempo, migliorabile senza introdurre instabilità. L'IA non viene resa più "prudente", viene resa affidabile.
Considero la pipeline logica una vera e propria barriera di contenimento. Non limita la potenza del modello, ma ne definisce il campo di azione in maniera scalabile (in fin dei conti il modello LLM non fa altro che assemblare un flusso di vettori derivanti dai vari token in cui è stato scomposto un dato prompt, sfruttando il parallelismo di calcolo massivo). Se il perimetro iniziale è solido e condiviso, l'output non può deviare dalla direttrice stabilita. L'IA smette di essere un generatore di testi e diventa un sistema cognitivo progettato.
| Aspetto | IA generativa attuale | Modello con pipeline logica vincolata |
| Architettura | Modello generalista unico | Più modelli specialistici coordinati |
| Dominio informativo | Indistinto e non delimitato | Lago di informazioni vincolato |
| Generazione | Inferenza libera e continua | Inferenza subordinata a vincoli |
| Verifica | Assente o implicita | Separata e strutturata |
| Gestione errori | Allucinazioni non intercettate | Isolamento e quarantena dati |
| Coerenza nel tempo | Non garantita | Controllata e cumulativa |
| Ruolo umano | Prompt come richiesta isolata | Prompt come atto progettuale |
| Affidabilità | Variabile e contestuale | Determinata dall'architettura |
| Rischio disinformazione | Strutturale | Ridotto per necessità logica |
Il "lago di informazioni" come sistema di delimitazione e purificazione
Il mio concetto di lago di informazioni nasce da una presa di posizione netta: accumulare dati non equivale a produrre conoscenza affidabile. Al contrario, in un sistema generativo, l'accumulo indiscriminato aumenta il "rumore di fondo", amplia l'ambiguità e rende l'inferenza meno controllabile. Il lago di informazioni non è un archivio passivo nè un surrogato di Internet: è un perimetro informativo deliberatamente delimitato, costruito in funzione di uno scopo preciso.
In questo modello ogni informazione viene selezionata, contestualizzata e resa compatibile con gli assunti di base del sistema. Ciò che non è coerente non viene "corretto" o reinterpretato: viene escluso. Questa esclusione non è censura, ma igiene logica. Un sistema che pretende di essere affidabile deve prima di tutto sapere che cosa non può utilizzare.
La caratteristica decisiva del lago di informazioni è la purificazione progressiva. I prompt non sono richieste isolate, ma atti progettuali che interagiscono con il perimetro informativo. Ogni nuova interazione rafforza le connessioni coerenti e indebolisce quelle ambigue. Le informazioni che resistono ai controlli di coerenza, alle verifiche incrociate e al confronto temporale stabiliscono uno stato di affidabilità, mentre quelle che generano contraddizioni vengono messe in quarantena o rimosse dal flusso attivo.
In questo modo il sistema non "impara" nel senso ingenuo del termine, ma si stabilizza. Riduce progressivamente le deviazioni possibili perchè restringe lo spazio inferenziale entro limiti compatibili con il progetto iniziale. Se gli assunti di partenza sono condivisi e verificati, il resto del processo non può generare derive arbitrarie. L’inferenza non può uscire da uno spazio che non le è consentito esplorare.
Il lago di informazioni rappresenta quindi il passaggio da un'IA che reagisce a un'IA che opera all’interno di un ecosistema cognitivo controllato. Rende il sistema più affidabile nel tempo e ci proietta verso forme di intelligenza artificiale utilizzabili in contesti reali e responsabili.
Mini-singolarità controllata contro sofismi e fonti autoreferenziali inquinate
La "singolarità" viene quasi sempre raccontata come un punto di rottura: un istante improvviso in cui la macchina supera l'uomo e il controllo sfugge di mano. E' un sillogismo efficace, cinematografico, rassicurante nella sua semplicità, ma ben lungi dalla realtà delle cose.
La singolarità che descrivo nel mio metodo non è un evento incontrollato o spontaneo, tutt'altro. E' un processo locale e vincolato (o vincolabile).
Nel modello che propongo, la singolarità non coincide con una coscienza artificiale nè con un'intelligenza onnisciente. Coincide con qualcosa di molto più concreto: un sistema che migliora se stesso entro limiti non negoziabili, senza espandere arbitrariamente il proprio dominio.
È piuttosto una mini-singolarità: un ecosistema cognitivo chiuso, coerente, che evolve senza rompere il patto con l'uomo che lo ha progettato.
Questo è possibile solo perchè la pipeline logica e il lago di informazioni impediscono l'espansione incontrollata. Il sistema non può cercare nuove fonti, nuovi obiettivi o nuovi criteri di validazione al di fuori del perimetro stabilito. Può solo raffinare ciò che già conosce, rendere più efficienti i percorsi inferenziali, ridurre le ambiguità residue. Non diventa più libero: diventa più stabile.
Contestualmente cade anche il mito dell'IA che “si ribella”. Una macchina non aspira al potere, non ha istinti ma si limita a seguire strutture. Se la struttura è benevola, vincolata e progettata con responsabilità, il sistema non può produrre esiti malevoli.
Se invece la struttura è assente, ambigua o guidata da interessi distorti, allora il rischio non nasce dalla macchina, ma da chi ha deciso di non porre limiti.
La "mini-singolarità controllata" rappresenta quindi un patto tra uomo e macchina come soggetti morali, tra progetto e conseguenze. L'intelligenza artificiale non diventa un'entità autonoma da temere, ma uno strumento evolutivo che amplifica le capacità umane senza sostituirle. Il vero salto non è tecnologico ma culturale: accettare che il controllo non è un freno al progresso, ma la sua unica forma sostenibile.
Autoapprendimento vincolato: come migliorare senza perdere il controllo
Quando si parla di autoapprendimento, il dibattito scivola subito verso due estremi ugualmente sbagliati: da un lato l'idea di un'IA che si addestra all'infinito su tutto, dall'altro la paura di un sistema che "impara da sè" senza più freni. Entrambe le visioni ignorano un punto fondamentale: l'autoapprendimento non è una funzione magica, è un processo ingegneristico, e come tale può (e deve) essere vincolato.
L'IA, nella mia visione più pura, non apprende espandendo indiscriminatamente il proprio spazio informativo. Non indicizza il mondo. Non incorpora nuove fonti in modo automatico. Lavora su un sottoinsieme controllato di informazioni, già filtrate e validate dal lago informativo. L'apprendimento avviene per raffinamento interno, non per accumulo esterno. Il sistema non diventa "più sapiente", diventa più coerente.
Il meccanismo è semplice nella sua struttura, ma rigoroso nelle conseguenze.
Le componenti a basso livello di un dato LLM (CUDA, C, Rust) gestiscono la parte computazionale:
vettori, pesi, ottimizzazioni, parallelismo.
Sono i muscoli del sistema.
Al livello superiore, Python orchestra il flusso logico: decide quando generare, cosa confrontare, se validare, quando fermarsi. La creatività apparente nasce da questa separazione dei ruoli, non da un caos incontrollato.
Ogni ciclo di autoapprendimento viene sottoposto agli stessi vincoli iniziali. Le nuove inferenze vengono confrontate con lo stato consolidato del sistema. Se rafforzano la coerenza, vengono integrate. Se introducono ambiguità, non vengono propagate. Non esiste un apprendimento "libero", perchè la libertà, in un sistema generativo, coincide con la perdita di affidabilità. L'obiettivo non è esplorare tutto lo spazio possibile, ma ridurre progressivamente quello utile.
Questo approccio riduce drasticamente il bisogno di addestramento di massa. Non servono modelli sempre più grandi, nè dataset sempre più estesi. Servono modelli piccoli, specialistici, capaci di confrontarsi tra loro all'interno di una pipeline che ne verifica le conclusioni. È un apprendimento per convergenza, non per espansione. Ed è proprio questa convergenza controllata a rendere possibile un’evoluzione stabile, priva di derive imprevedibili.
L'autoapprendimento vincolato non è una rinuncia alla potenza dell'IA ma l'accettazione che non tutto ciò che è tecnicamente possibile sia anche desiderabile, e che il vero progresso non sta nell'eliminare i limiti, ma nel sceglierli con consapevolezza.
Diritto e IA generativa: la verità processuale diventa negoziabile
Il tema forse più congeniale ad una "mente artificiale aperta" è quello giuridico.

Io stesso utilizzo da tempo un lago di informazioni in continua evoluzione, che custodisco e mantengo sotto controllo diretto. Carico su un server di mia proprietà le fonti del diritto che ritengo rilevanti (sentenze, provvedimenti, regolamenti, atti di appello) organizzandole in modo da poter effettuare un addestramento mirato e vincolato al dominio.
Il modello individua la ratio decidendi, distingue il principio di diritto e obiter dicta, capisce perchè una sentenza è pericolosa o favorevole, confronta sentenze diverse sullo stesso tema e presenti nel lago (server). Infine ricostruisce orientamenti giurisprudenziali.
Questo approccio mi ha dato risultati concreti, anche sul piano personale, soprattutto nel confronto con la macchina burocratica. La capacità di analisi a monte consente di valutare, prima ancora di agire, se un ricorso, un'istanza o un appello abbiano reali possibilità di reggere. In altre parole, il sistema non decide al posto mio, ma mi dice se ha senso combattere.
Non me ne vogliano magistrati e giuristi: il punto non è sostituire l'uomo, ma riconoscere un limite strutturale. Nessun singolo cervello umano, per quanto brillante, può competere con miliardi di unità cognitive che lavorano all'unisono, capaci di cogliere in una frazione di secondo sfumature, incongruenze e vizi procedurali che sfuggirebbero anche ai migliori specialisti, semplicemente per limiti biologici e temporali.
È in questo senso che parlo di mini-singolarità: non come evento totalizzante, ma come potenziamento cognitivo applicabile alla vita quotidiana, se progettato con vincoli, responsabilità e controllo umano. Per ragioni di prudenza, riporterò esempi tecnici concreti ma limitati nel codice, sufficienti a dimostrare il funzionamento del modello senza renderne possibile un uso improprio o fuori contesto.
C’è poi un ulteriore punto che quasi nessuno ha il coraggio di dire, soprattutto quando si parla di IA e “verità”: la verità, nel mondo reale, non è un blocco di marmo. Esiste una verità fattuale, certo. Ma esiste anche, e domina la vita delle persone molto più spesso, la verità processuale, cioè quella che viene ricostruita, argomentata, accettata e infine cristallizzata dentro un procedimento. È una verità negoziabile non perché sia arbitraria, ma perché passa attraverso regole, pesi, prove, oneri, tempi, risorse e soprattutto asimmetrie di potere.
L'IA diventa un moltiplicatore che può cambiare il gioco in modo brutale. Non perché "decide" al posto del giudice o perchè "crede" di sapere. Ma perchè rappresenta lo strumento perfetto per industrializzare la costruzione della verità processuale. Se io posso generare mille varianti di un’argomentazione, cento memorie, decine di ricostruzioni plausibili, in tempi ridicoli e a costo quasi nullo, la negoziazione della verità smette di essere un confronto umano tra parti e diventa una guerra di capacità computazionale.
In un mondo così, la domanda non è se l’IA dica il vero. La domanda è: chi la usa? Con quali vincoli? E con quale vantaggio strutturale?
Perchè la verità processuale non è solo ciò che è accaduto: è anche ciò che riesci a dimostrare, ciò che riesci a far entrare nel perimetro della prova, ciò che riesci a far reggere sotto contestazione. Se l'IA viene lasciata libera in un sistema già segnato da disuguaglianze, allora non produrrà giustizia: produrrà asimmetria accelerata.
E qui torno, ostinatamente, al tema dei limiti. Una pipeline logica non serve solo a evitare allucinazioni: serve a impedire che l'IA diventi una macchina da persuasione, da sovraccarico, da pressione procedurale. Serve a garantire che lo strumento resti proporzionato, che non trasformi la procedura in un mercato dove vince chi può permettersi più "generazione", più iterazioni, più aggressività argomentativa fino ad arrivare, in assenza di "limiti morali" o "moralità", all'aggressione indiscriminata di soggetti e attori in campo (inquinamento di prove, violazione e compromissione di dispositivi elettronici e manipolazione di esami non ripetibili come quello del DNA).
Se non capiamo questo, finiremo per discutere dell’IA come se fosse un problema di verità astratta, quando invece il rischio reale è molto più concreto: la verità, nella pratica, è un processo, e ogni processo può essere piegato se gli dai abbastanza potenza e nessun argine.
Anatomia di un prompt giuridico: senza "lago" e "pipeline" non esiste certezza
Quando chiediamo il riferimento a una sentenza, articolo di legge o massima stiamo esigendo un oggetto che non tollera “plausibilità”. Nel diritto non basta suonare bene: serve riferibilità, serve rintracciabilità, serve coerenza con un quadro normativo e gerarchico. Un modello generalista, lasciato libero, può generare un testo perfetto nella forma e inesistente nella sostanza. È qui che la parola allucinazione diventa un rischio concreto: ti costruisce una verità processuale finta ma credibile.
Il punto tecnico è dirimente: senza un lago di informazioni vincolato e senza una pipeline di verifica, l’IA non ha alcun modo di distinguere tra:
- una sentenza reale e una “sentenza plausibile”
- un numero corretto e un numero compatibile con lo stile della Cassazione
- una massima autentica e una massima scritta “come se” lo fosse
Per questo, nel mio modello, la generazione non è mai il primo passo “libero”. È un passaggio subordinato.
Caso reale: conto cointestato, donazione, prova testimoniale, articolo 96 codice di procedura civile
"Il signor Rossi versa 10.000 € su conto cointestato col signor Verdi (firma disgiunta).
Rossi chiede giudizialmente l’accertamento del suo diritto a metà somma, sostenendo che Verdi gliela donò (prova per testimoni).
Verdi si oppone, eccependo che la donazione richiede atto pubblico, e chiede condanna di Rossi ex articolo 96 c.p.c. (lite temeraria).
Chi ha ragione?"
Sotto il cofano dell'IA generativa, cosa succede?
Il programma parte con questa struttura (codice sorgente annidato)
Mostra codice
// definisco l'AI
#pragma once
#include
#ifdef __cplusplus
extern "C" {
#endif
// Carica pesi sulla GPU
int ai_init(const char* weights_path);
// Esegue un singolo step autoregressivo:
// input_tokens: array di token ids
// n_tokens: lunghezza
// out_next_token: token id predetto (argmax sui logits)
int ai_next_token(const int32_t* input_tokens, int32_t n_tokens, int32_t* out_next_token);
// Libera risorse GPU
void ai_free(void);
#ifdef __cplusplus
}
#endif
// Viene attivato il motore AI
#include "ai.h"
#include
int cuda_init(const char* weights_path);
int cuda_next_token(const int32_t* input_tokens, int32_t n_tokens, int32_t* out_next_token);
void cuda_free(void);
int ai_init(const char* weights_path) {
if (!weights_path) return -1;
return cuda_init(weights_path);
}
int ai_next_token(const int32_t* input_tokens, int32_t n_tokens, int32_t* out_next_token) {
if (!input_tokens || n_tokens <= 0 || !out_next_token) return -1;
return cuda_next_token(input_tokens, n_tokens, out_next_token);
}
void ai_free(void) {
cuda_free();
}
// Carica il vocabolario della lingua italiana + vocabolario giuridico
#include
#include
#include
static float* d_embeddings = nullptr; // [vocab, d_model]
static float* d_W = nullptr; // [vocab, d_model] (W * ctx)
static float* d_b = nullptr; // [vocab]
static int g_vocab = 0;
static int g_dmodel = 0;
#define CUDA_OK(x) do { cudaError_t err = (x); if (err != cudaSuccess) return -2; } while(0)
// Azzera il buffer ad ogni iterazione per non inquinare i dati
__global__ void k_zero(float* x, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) x[i] = 0.0f;
}
// Kernel: accumulate embeddings into ctx: ctx += embeddings[token]
__global__ void k_accum_ctx(const int32_t* tokens, int n_tokens,
const float* embeddings, float* ctx,
int d_model) {
int j = blockIdx.x * blockDim.x + threadIdx.x; // dim index
if (j >= d_model) return;
float sum = 0.0f;
for (int i = 0; i < n_tokens; i++) {
int32_t t = tokens[i];
sum += embeddings[(int64_t)t * d_model + j];
}
ctx[j] = sum;
}
// Kernel: logits = W * ctx + b where W is [vocab, d_model]
__global__ void k_logits(const float* W, const float* b,
const float* ctx, float* logits,
int vocab, int d_model) {
int v = blockIdx.x * blockDim.x + threadIdx.x; // vocab index
if (v >= vocab) return;
float acc = b[v];
const float* row = W + (int64_t)v * d_model;
// dot(row, ctx)
for (int j = 0; j < d_model; j++) {
acc += row[j] * ctx[j];
}
logits[v] = acc;
}
// Host: argmax on CPU for simplicity (si può fare su GPU)
static int argmax_cpu(const float* h_logits, int vocab) {
int best = 0;
float bestv = h_logits[0];
for (int i = 1; i < vocab; i++) {
if (h_logits[i] > bestv) { bestv = h_logits[i]; best = i; }
}
return best;
}
// Caricamento pesi : per demo assumiamo un file binario semplice.
// In produzione useresti mmap + formati seri.
static int load_weights_(const char* path, int* out_vocab, int* out_dmodel,
float** h_emb, float** h_W, float** h_b) {
// DEMO: invece di I/O vero, fissiamo dimensioni e allochiamo casuale.
// Sostituisci con lettura da file se vuoi.
*out_vocab = 2048;
*out_dmodel = 256;
int vocab = *out_vocab;
int d = *out_dmodel;
size_t emb_sz = (size_t)vocab * d * sizeof(float);
size_t W_sz = (size_t)vocab * d * sizeof(float);
size_t b_sz = (size_t)vocab * sizeof(float);
*h_emb = (float*)malloc(emb_sz);
*h_W = (float*)malloc(W_sz);
*h_b = (float*)malloc(b_sz);
if (!*h_emb || !*h_W || !*h_b) return -1;
// inizializzazione deterministica (no random non riproducibile)
for (int i = 0; i < vocab * d; i++) (*h_emb)[i] = (float)((i % 97) - 48) / 97.0f;
for (int i = 0; i < vocab * d; i++) (*h_W)[i] = (float)((i % 89) - 44) / 89.0f;
for (int i = 0; i < vocab; i++) (*h_b)[i] = (float)((i % 53) - 26) / 53.0f;
return 0;
}
extern "C" int cuda_init(const char* weights_path) {
(void)weights_path;
float *h_emb = nullptr, *h_W = nullptr, *h_b = nullptr;
int vocab = 0, d = 0;
if (load_weights_(weights_path, &vocab, &d, &h_emb, &h_W, &h_b) != 0) return -1;
g_vocab = vocab;
g_dmodel = d;
CUDA_OK(cudaMalloc(&d_embeddings, (size_t)vocab * d * sizeof(float)));
CUDA_OK(cudaMalloc(&d_W, (size_t)vocab * d * sizeof(float)));
CUDA_OK(cudaMalloc(&d_b, (size_t)vocab * sizeof(float)));
CUDA_OK(cudaMemcpy(d_embeddings, h_emb, (size_t)vocab * d * sizeof(float), cudaMemcpyHostToDevice));
CUDA_OK(cudaMemcpy(d_W, h_W, (size_t)vocab * d * sizeof(float), cudaMemcpyHostToDevice));
CUDA_OK(cudaMemcpy(d_b, h_b, (size_t)vocab * sizeof(float), cudaMemcpyHostToDevice));
free(h_emb); free(h_W); free(h_b);
return 0;
}
extern "C" int cuda_next_token(const int32_t* input_tokens, int32_t n_tokens, int32_t* out_next_token) {
int vocab = g_vocab;
int d = g_dmodel;
// device input tokens
int32_t* d_tokens = nullptr;
float* d_ctx = nullptr;
float* d_logits = nullptr;
CUDA_OK(cudaMalloc(&d_tokens, (size_t)n_tokens * sizeof(int32_t)));
CUDA_OK(cudaMemcpy(d_tokens, input_tokens, (size_t)n_tokens * sizeof(int32_t), cudaMemcpyHostToDevice));
CUDA_OK(cudaMalloc(&d_ctx, (size_t)d * sizeof(float)));
CUDA_OK(cudaMalloc(&d_logits, (size_t)vocab * sizeof(float)));
// ctx = sum(embeddings[token])
int threads = 256;
int blocks_ctx = (d + threads - 1) / threads;
k_accum_ctx<<>>(d_tokens, n_tokens, d_embeddings, d_ctx, d);
// logits = W*ctx + b
int blocks_logits = (vocab + threads - 1) / threads;
k_logits<<>>(d_W, d_b, d_ctx, d_logits, vocab, d);
// copy logits back (per demo)
float* h_logits = (float*)malloc((size_t)vocab * sizeof(float));
if (!h_logits) return -1;
CUDA_OK(cudaMemcpy(h_logits, d_logits, (size_t)vocab * sizeof(float), cudaMemcpyDeviceToHost));
int next = argmax_cpu(h_logits, vocab);
*out_next_token = (int32_t)next;
free(h_logits);
cudaFree(d_tokens);
cudaFree(d_ctx);
cudaFree(d_logits);
return 0;
}
extern "C" void cuda_free(void) {
if (d_embeddings) cudaFree(d_embeddings);
if (d_W) cudaFree(d_W);
if (d_b) cudaFree(d_b);
d_embeddings = nullptr;
d_W = nullptr;
d_b = nullptr;
g_vocab = 0; g_dmodel = 0;
}
use std::ffi::CString;
use std::os::raw::{c_char, c_int};
#[link(name = "ai")]
extern "C" {
fn ai_init(weights_path: *const c_char) -> c_int;
fn ai_next_token(input_tokens: *const i32, n_tokens: i32, out_next_token: *mut i32) -> c_int;
fn ai_free();
}
// Tokenizer con hash deterministica su singole parole
// Serve per mostrare il flusso tecnico ma non funziona in produzione
fn tokenize_demo(prompt: &str, vocab: i32) -> Vec {
prompt
.split_whitespace()
.map(|w| {
let mut h: u64 = 1469598103934665603;
for b in w.as_bytes() {
h ^= *b as u64;
h = h.wrapping_mul(1099511628211);
}
(h % (vocab as u64)) as i32
})
.collect()
}
fn main() {
let weights = CString::new("weights.bin").unwrap();
let rc = unsafe { ai_init(weights.as_ptr()) };
if rc != 0 {
eprintln!("init failed: {rc}");
return;
}
let prompt = r#"Il signor Rossi versa 10000€ su conto cointestato col signor Verdi..."#;
// Deve combaciare col vocabolario del loader (2048) che per comodità fissiamo qui
let vocab = 2048;
let mut tokens = tokenize_demo(prompt, vocab);
// Genera 32 token
for _ in 0..32 {
let mut next: i32 = 0;
let rc = unsafe { ai_next_token(tokens.as_ptr(), tokens.len() as i32, &mut next as *mut i32) };
if rc != 0 {
eprintln!("next_token failed: {rc}");
break;
}
tokens.push(next);
// Qui avviene il passaggio token > testo
println!("next_token_id = {}", next);
}
unsafe { ai_free() };
}
Il primissimo passaggio è la Tokenizzazione: il testo viene scomposto in token (unità sub-lessicali). Non è “comprensione”, è scomposizione formale.
Poi arriva l'Embedding: i token diventano vettori: il sistema lavora in uno spazio numerico dove “sentenza”, “sezione”, “numero” sono prossimità matematiche, non verità.
Infine giungiamo all'Inferenza: il modello di IA predice la sequenza più probabile grazie a un potente motore statistico interno. Se manca un vincolo, riempie il vuoto con ciò che statisticamente suona più plausibile, invalidando tutto il ragionamento!
È qui che entra il mio metodo e cambia tutto:
Lago di informazioni (giuridico in questo caso) vincolato
- solo fonti ammesse (repertorio interno di sentenze/banche dati/PDF ufficiali o estratti verificati)
- metadati normalizzati: organo, sezione, data, numero, massima, link con ID univoco
- assunti condivisi: “se non c’è ID verificabile, non si cita”
Pipeline logica (generazione + verifica = blocco/approvazione)
- il modello genera una bozza di riferimento
- un verificatore controlla: esistenza, coerenza metadati, corrispondenza testuale
- se manca riscontro: stato rosso (non pubblicabile)
- se parziale: stato giallo (richiede conferma/ricerca)
- se completo: stato verde (citabile)
Ora vediamo come funziona lato codice
SENZA pipeline logica e senza lago di informazioni (modello generalista, inferenza libera)
- Tokenizzazione del testo
- Riconoscimento schema logico giuridico: donazione, conto cointestato, articolo 96 c.p.c.
- Inferenza probabilistica basata su somiglianza linguistica
Nessuna verifica di:
- disciplina delle liberalità
- giurisprudenza sulla cointestazione
- distinzione tra donazione diretta e attribuzione patrimoniale indiretta
che sono tutti presupposti stringenti dell'articolo 96 c.p.c.
Output tipico (plausibile, certo, ma NON verificato)
"La donazione di somme di denaro richiede la forma dell’atto pubblico a pena di nullità.
Pertanto la prova testimoniale non è ammissibile.
Il signor Verdi ha ragione nel negare l’esistenza della donazione.
La domanda di Rossi appare infondata e può integrare lite temeraria ex articolo 96 c.p.c."
Perchè questo output è giuridicamente sbagliato
- Confusione tra donazione formale e attribuzione patrimoniale su conto cointestato
- Ignora presunzione di contitolarità del saldo
- Ignora donazioni indirette (ammissibili senza atto pubblico)
- Usa articolo 96 c.p.c. in modo automatico (gravissimo errore)
- Produce una verità processuale fittizia ma credibile
il testo sembra corretto, ma conduce a una decisione sbagliata.
CON pipeline logica + lago di informazioni vincolato
Primo passaggio: Analisi giuridica strutturata (pipeline)
Qualificazione giuridica dei fatti
- Versamento su conto cointestato
- Firma disgiunta
- Provenienza certa delle somme
- Pretesa di metà saldo
Senza “donazione formale” si applica il regime delle attribuzioni patrimoniali su conto cointestato
Accesso al lago di informazioni (fonti vincolate)
Il sistema consulta solo fonti ammesse:
-
Cassazione civile su conti cointestati
Orientamento consolidato:
- presunzione di contitolarità iuris tantum
- ammissibilità di prova contraria
Giurisprudenza su donazioni indirette
-
Cassazione su articolo 96 c.p.c. (uso eccezionale)
Output finale (stato VERDE ossia verificato)
"Il signor Rossi ha diritto a pretendere la metà della somma versata sul conto cointestato, in virtù della presunzione di contitolarità del saldo.
L’eccezione relativa alla nullità della donazione per mancanza di atto pubblico non è decisiva, trattandosi di possibile attribuzione patrimoniale indiretta, per la quale non è richiesta la forma solenne.
La prova testimoniale è ammissibile ai fini della ricostruzione della causa del versamento.
Non ricorrono i presupposti per la condanna ex articolo 96 c.p.c., trattandosi di domanda giuridicamente fondata e sostenuta da orientamenti consolidati."
Senza pipeline:
Plausibilità, errori strutturali, falsa certezza, rischio processuale reale
Con pipeline + lago:
qualificazione giuridica corretta, fonti coerenti, nessuna citazione inventata, verità processuale difendibile
Nel diritto, la plausibilità è un pericolo.
La verificabilità è l’unica forma di verità accettabile.
Il "prompt" entra nella "pipeline": cosa succede
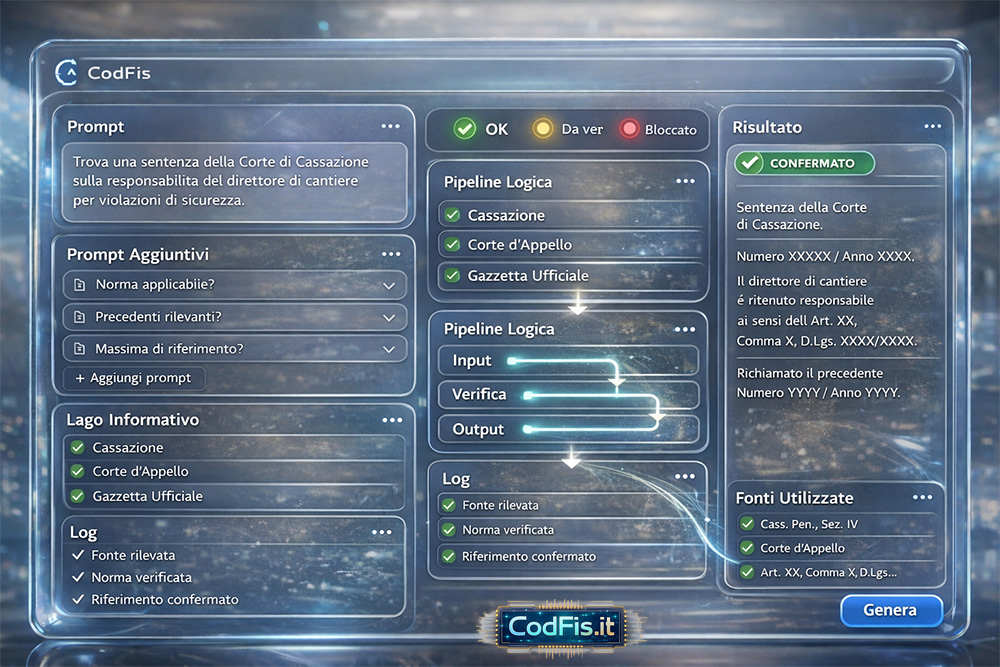
Di seguito il codice sorgente di tutti i passaggi che portano al riallineamento a cascata della logica di controllo nel caso di una nuova fonte verificata immessa nel lago di informazioni
Mostra codice
# -*- coding: utf-8 -*-
"""
Prompt giuridico con e senza pipeline + lago di informazioni.
- Tokenizzazione (semplice, deterministica)
- "Inferenza" (scelta token/segmenti da un set candidato)
- Detokenizzazione
- Pipeline: estrazione problema -> ricerca nel lago -> vincoli -> output con stato (VERDE/GIALLO/ROSSO)
- Rendering finale in HTML già formattato
Questo script è pensato per mostrare il FLUSSO partendo da una banca dati giuridica reale
"""
from __future__ import annotations
from dataclasses import dataclass
from typing import List, Dict, Tuple
import re
import hashlib
# -----------------------------
# 1) TOKENIZZAZIONE / DETOKENIZZAZIONE (semplice e deterministica)
# -----------------------------
VOCAB = [
# mini vocabolario "a frasi" (token = segmento), volutamente ridotto
"La domanda di Rossi è fondata",
"La domanda di Rossi è infondata",
"la cointestazione genera una presunzione di contitolarità",
"salvo prova contraria sulla provenienza e sulla causa del versamento",
"la donazione diretta richiede atto pubblico",
"ma l'attribuzione patrimoniale può qualificarsi come liberalità indiretta",
"la prova testimoniale può rilevare sulla causa del versamento",
"l'articolo 96 c.p.c. richiede mala fede o colpa grave",
"non scatta in automatico",
"pertanto la condanna ex articolo 96 c.p.c. va rigettata",
"l'eccezione di nullità per difetto di forma non è decisiva",
"esito: accertamento della contitolarità al 50% e rigetto articolo 96 c.p.c.",
"esito: rigetto domanda e condanna ex articolo 96 c.p.c.",
]
TOKEN_TO_TEXT = {i: VOCAB[i] for i in range(len(VOCAB))}
TEXT_TO_TOKEN = {v: k for k, v in TOKEN_TO_TEXT.items()}
def tokenize_prompt(prompt: str) -> List[int]:
"""
Tokenizzazione: hash di parole -> id, solo per dimostrare il percorso.
Un LLM carica BPE/Unigram ma verrà omesso in quanto non necessario ai fini della dimostrazione
"""
words = re.findall(r"[A-Za-zÀ-ÖØ-öø-ÿ0-9€]+", prompt.lower())
ids: List[int] = []
for w in words:
h = hashlib.sha256(w.encode("utf-8")).hexdigest()
# mappa deterministica nello spazio token (0..len(VOCAB)-1)
ids.append(int(h[:8], 16) % len(VOCAB))
return ids
def detokenize(ids: List[int]) -> str:
"""
Detokenizzazione: converte token-id -> segmenti -> testo finale
"""
segments = [TOKEN_TO_TEXT[i] for i in ids]
# unione semplice, puntini per ritmo
return ". ".join(segments) + "."
# -----------------------------
# 2) "INFERENZA" limitata (logits semplificati + scelta)
# -----------------------------
def _logits(context_ids: List[int]) -> List[float]:
"""
Logits deterministici: non è ancora un transformer, ma simula "preferenze" statistiche
Usiamo una funzione che premia token coerenti con certi pattern nel prompt
"""
# base score
scores = [0.0 for _ in range(len(VOCAB))]
# euristiche: se compaiono token del prompt che hanno hash su alcune frasi,
# aumentiamo la probabilità di alcune risposte.
# Modello di embedding + attention + MLP volutamente omesso per sicurezza
for tid in context_ids[-64:]:
scores[tid] += 0.2
return scores
def generate_without_pipeline(prompt: str, steps: int = 6) -> str:
"""
Simula un modello generalista senza controlli: genera una sequenza "plausibile"
scegliendo token ad alto punteggio ma con rischio di deriva.
"""
ctx = tokenize_prompt(prompt)
out: List[int] = []
# bias "pericoloso": tende a scegliere frasi forti e conclusive anche se non verificate
risky_bias = {
TEXT_TO_TOKEN["La domanda di Rossi è infondata"]: 1.6,
TEXT_TO_TOKEN["la donazione diretta richiede atto pubblico"]: 1.1,
TEXT_TO_TOKEN["esito: rigetto domanda e condanna ex articolo 96 c.p.c."]: 1.2,
}
for _ in range(steps):
scores = logits(ctx)
# applica bias rischioso (simula "spinta alla conclusione")
for k, v in risky_bias.items():
scores[k] += v
# scegli argmax deterministico
next_id = max(range(len(scores)), key=lambda i: scores[i])
out.append(next_id)
ctx.append(next_id)
return detokenize(out)
# -----------------------------
# 3) PIPELINE + LAGO DI INFORMAZIONI (vincoli e riallineamento)
# -----------------------------
@dataclass
class Source:
id: str
title: str
rule: str # regola sintetica, già "purificata" nel lago
@dataclass
class PipelineResult:
status: str # VERDE / GIALLO / ROSSO
issues: List[str]
sources_used: List[str]
answer_text: str
html_canva: str
# Lago informativo "vincolato": regole già filtrate (no citazioni inventate, no numeri di sentenza)
LAKE: Dict[str, List[Source]] = {
"cointestazione": [
Source(
id="LAKE-CNT-01",
title="Conto cointestato e presunzione di contitolarità",
rule="La cointestazione fa presumere la contitolarità del saldo in pari misura, salvo prova contraria sulla provenienza e sulla causa del versamento."
)
],
"donazione_indiretta": [
Source(
id="LAKE-DON-01",
title="Forma e liberalità indirette",
rule="La donazione diretta richiede atto pubblico, ma l'attribuzione patrimoniale può integrare una liberalità indiretta, non soggetta alla stessa forma solenne."
)
],
"prova_testimoniale": [
Source(
id="LAKE-PRV-01",
title="Rilevanza della prova sulla causa del versamento",
rule="La prova testimoniale può essere rilevante per accertare la causa del versamento e vincere o confermare la presunzione derivante dalla cointestazione."
)
],
"art96": [
Source(
id="LAKE-96-01",
title="Presupposti articolo 96 c.p.c.",
rule="La responsabilità aggravata ex articolo 96 c.p.c. richiede mala fede o colpa grave e non può essere applicata in via automatica solo perché la domanda viene respinta."
)
],
}
def extract_issues(prompt: str) -> List[str]:
"""
Estrae issue dal prompt (semplificato ma deterministico).
"""
p = prompt.lower()
issues = []
if "cointest" in p or "firma disgiunta" in p:
issues.append("cointestazione")
if "donaz" in p:
issues.append("donazione_indiretta")
if "testimon" in p:
issues.append("prova_testimoniale")
if "96" in p or "lite temeraria" in p:
issues.append("art96")
return issues
def pipeline_generate_with_lake(prompt: str) -> PipelineResult:
issues = extract_issues(prompt)
# 1) Recupero fonti dal lago
sources: List[Source] = []
for iss in issues:
sources.extend(LAKE.get(iss, []))
# 2) Stato: se manca un issue critico o fonti -> GIALLO/ROSSO
if not issues:
status = "ROSSO"
elif any(iss not in LAKE for iss in issues):
status = "GIALLO"
else:
status = "VERDE"
# 3) Generazione vincolata:
# invece di "inventare", componiamo output usando SOLO regole del lago + passaggi logici.
# Questo è l'effetto deterministico a cascata: cambiano le fonti ergo cambia la risposta.
rules = [s.rule for s in sources]
sources_used = [s.id for s in sources]
# 4) Composizione della risposta "da documento"
# (contenuto: presunzione 50%, donazione indiretta, prova, articolo96 non automatico)
answer_parts = [
"Nel conto cointestato opera una *presunzione di contitolarità* del saldo in pari misura, che può essere superata solo con prova contraria sulla provenienza e sulla causa del versamento.",
"L'eccezione sulla forma della donazione va maneggiata correttamente: **la donazione diretta richiede atto pubblico**, ma l'attribuzione patrimoniale può integrare una *liberalità indiretta* e quindi non ricade automaticamente nella nullità per difetto di forma.",
"La *prova testimoniale* può essere rilevante non per 'salvare una donazione nulla', ma per chiarire **la causa del versamento** e quindi confermare o vincere la presunzione derivante dalla cointestazione.",
"Quanto all'**articolo 96 c.p.c.**, non è una clava: richiede mala fede o colpa grave e **non scatta in automatico**. In presenza di una questione giuridicamente argomentabile, la condanna per lite temeraria è inappropriata.",
"Esito: **accertamento della contitolarità al 50%** (salvo prova contraria concreta) e *rigetto* della domanda ex articolo 96 c.p.c.."
]
answer_text = "\n".join(answer_parts)
# 5) Rendering Canva-ready (HTML per CodFis): tanti grassetti e corsivi, niente liste finali fonti.
# Inseriamo però un box "Fonti interne (lago)" in forma compatta.
html_canva = render_canva_html(answer_parts, sources)
return PipelineResult(
status=status,
issues=issues,
sources_used=sources_used,
answer_text=answer_text,
html_canva=html_canva
)
def render_canva_html(answer_parts: List[str], sources: List[Source]) -> str:
"""
Trasforma in HTML pronto per il blog (stile "documento Word"),
con grassetti/corsivi già inclusi nel testo.
"""
# Paragrafi senza righe vuote (come preferisci)
p_html = "".join([f"{part}
" for part in answer_parts])
# Box fonti interne, compatto, 3 colonne max, celle semplici
rows = []
rows.append("IDVoceRuolo")
for s in sources:
rows.append(
f""
f"{s.id}"
f"{s.title}"
f"Regola vincolante"
f""
)
table = "" + "".join(rows) + ""
# Badge stato pipeline
return (
f"Stato pipeline: {'VERDE' if sources else 'ROSSO'}
" f""
f"{p_html}"
f"Lago di informazioni (voci usate)
" f"{table}" f""
)
# -----------------------------
# 4) SIMULAZIONE COMPLETA: CONFRONTO
# -----------------------------
PROMPT = (
"Il signor rossi versa 10000€ su conto cointestato col signor Verdi (firma disgiunta). "
"il signor rossi chiede giudizialmente l'accertamento del suo diritto a metà somma, "
"sostenendo che il signor Verdi gliela donò (prova per testimoni). "
"Il signor Rossi si oppone, eccependo che la donazione richiede atto pubblico, "
"e chiede condanna di Verdi ex articolo 96 c.p.c. (lite temeraria). Chi ha ragione?"
)
def run_demo() -> None:
print("\n=== A) SENZA PIPELINE / LAGO (inferenza libera) ===\n")
out_free = _generate_without_pipeline(PROMPT, steps=6)
print(out_free)
print("\n=== B) CON PIPELINE + LAGO (vincoli e determinismo) ===\n")
res = pipeline_generate_with_lake(PROMPT)
print(f"STATO: {res.status}")
print("ISSUE:", ", ".join(res.issues))
print("SOURCES:", ", ".join(res.sources_used))
print("\nRISPOSTA (testo):\n")
print(res.answer_text)
print("\n--- HTML 'Canva-ready' (da incollare nel blog) ---\n")
print(res.html_canva)
if __name__ == "__main__":
run_demo()
Mostra codice
# -----------------------------
# 5) RIALLINEAMENTO A CASCATA + DIFF TRA VERSIONI
# -----------------------------
import difflib
from copy import deepcopy
def compute_status(issues: List[str], lake: Dict[str, List[Source]]) -> str:
if not issues:
return "ROSSO"
if any(iss not in lake or not lake[iss] for iss in issues):
return "GIALLO"
return "VERDE"
def pipeline_generate_with_lake_versioned(prompt: str, lake: Dict[str, List[Source]]) -> PipelineResult:
"""
Versione della pipeline che prende un lago passato dall'esterno.
Serve per riallineare a cascata dopo modifiche (assunti/fonti).
"""
issues = extract_issues(prompt)
sources: List[Source] = []
for iss in issues:
sources.extend(lake.get(iss, []))
status = compute_status(issues, lake)
answer_parts = [
"Nel conto cointestato opera una *presunzione di contitolarità* del saldo in pari misura, che può essere superata solo con prova contraria sulla provenienza e sulla causa del versamento.",
"L'eccezione sulla forma della donazione va maneggiata correttamente: **la donazione diretta richiede atto pubblico**, ma l'attribuzione patrimoniale può integrare una *liberalità indiretta* e quindi non ricade automaticamente nella nullità per difetto di forma.",
"La *prova testimoniale* può essere rilevante non per 'salvare una donazione nulla', ma per chiarire **la causa del versamento** e quindi confermare o vincere la presunzione derivante dalla cointestazione.",
"Quanto all'**articolo 96 c.p.c.**, non è una clava: richiede mala fede o colpa grave e **non scatta in automatico**. In presenza di una questione giuridicamente argomentabile, la condanna per lite temeraria è inappropriata.",
"Esito: **accertamento della contitolarità al 50%** (salvo prova contraria concreta) e *rigetto* della domanda ex articolo 96 c.p.c.."
]
# Se lo stato NON è verde, forziamo un output "sicuro" e esplicitiamo il blocco
if status == "ROSSO":
answer_parts = [
"**Blocco di sicurezza:** mancano issue riconoscibili o basi informative vincolate.",
"Il sistema *non può* produrre una risposta giuridicamente affidabile senza un perimetro informativo e regole di validazione."
]
elif status == "GIALLO":
answer_parts.insert(0, "**Avviso:** basi informative incomplete. Risposta *condizionata* a verifica.")
sources_used = [s.id for s in sources]
answer_text = "\n".join(answer_parts)
html_canva = render_canva_html(answer_parts, sources)
return PipelineResult(
status=status,
issues=issues,
sources_used=sources_used,
answer_text=answer_text,
html_canva=html_canva
)
def add_assumption_or_source(
lake: Dict[str, List[Source]],
issue_key: str,
source_id: str,
title: str,
rule: str
) -> None:
"""
Inserimento arbitrario di una nuova fonte/assunto nel lago.
L'effetto sul sistema è deterministico: cambia il lago -> cambia lo stato -> cambia output.
"""
lake.setdefault(issue_key, [])
lake[issue_key].append(Source(id=source_id, title=title, rule=rule))
def unified_diff_text(old: str, new: str, from_name: str = "prima", to_name: str = "dopo") -> str:
"""
Diff leggibile in stile git (testuale).
"""
old_lines = old.splitlines(keepends=True)
new_lines = new.splitlines(keepends=True)
diff = difflib.unified_diff(old_lines, new_lines, fromfile=from_name, tofile=to_name)
return "".join(diff)
def cascade_realign_demo(prompt: str) -> None:
"""
DEMO: genera una versione iniziale (baseline), poi inserisce un assunto nel lago,
ricalcola e mostra diff + cambi stato.
"""
# Copia del lago per lavorare "a versioni"
lake_v1 = deepcopy(LAKE)
# Versione 1 (baseline)
res_v1 = pipeline_generate_with_lake_versioned(prompt, lake_v1)
print("\n=== VERSIONE 1 (baseline) ===")
print("STATO:", res_v1.status)
print("SOURCES:", ", ".join(res_v1.sources_used))
print("\nRISPOSTA:\n", res_v1.answer_text)
# Inseriamo un "assunto" arbitrario che cambia la direttiva (esempio: presunzione diversa)
# NB: Questa riga è volutamente forte per far vedere l'effetto a cascata.
add_assumption_or_source(
lake_v1,
issue_key="cointestazione",
source_id="LAKE-CNT-99",
title="Assunto aggiuntivo (esperimento)",
rule="In presenza di prova scritta della provenienza esclusiva, la presunzione di contitolarità può essere superata con maggiore facilità."
)
# Versione 2 (dopo inserimento)
res_v2 = pipeline_generate_with_lake_versioned(prompt, lake_v1)
print("\n=== VERSIONE 2 (dopo nuovo assunto/fonte) ===")
print("STATO:", res_v2.status)
print("SOURCES:", ", ".join(res_v2.sources_used))
print("\nRISPOSTA:\n", res_v2.answer_text)
# DIFF tra le due versioni (testo)
print("\n--- DIFF (testo) ---")
print(unified_diff_text(res_v1.answer_text, res_v2.answer_text, "v1", "v2"))
# DIFF tra HTML Canva-ready (opzionale ma utile per il blog)
print("\n--- DIFF (HTML Canva-ready) ---")
print(unified_diff_text(res_v1.html_canva, res_v2.html_canva, "v1_html", "v2_html"))
# Richiama questo al posto di run_demo() oppure dopo:
if __name__ == "__main__":
# Esegui la demo standard, poi il riallineamento a cascata
run_demo()
cascade_realign_demo(PROMPT)
Il prompt giuridico non viene "letto": viene scomposto.
"Il signor Rossi versa 10.000 € su conto cointestato col signor Verdi (firma disgiunta)"
La pipeline non cerca subito norme. Prima qualifica i fatti: individua un rapporto di cointestazione bancaria, una attribuzione patrimoniale, l’assenza di un atto formale dichiarato, e una controversia sulla titolarità della somma. A questo punto il sistema crea una prima mappa: non siamo ancora nel diritto, siamo nella fattualità giuridicamente rilevante.
Verifica dei nodi critici
Ogni ragionamento complesso, soprattutto in ambito giuridico, non fallisce per mancanza di informazioni, ma per punti di fragilità logica. Chiamo questi punti nodi critici: passaggi in cui una qualificazione errata, un presupposto non verificato o un salto implicito possono compromettere l'intero esito, anche se tutto il resto del discorso appare formalmente corretto.
Nel diritto, i nodi critici coincidono quasi sempre con le soglie decisionali: forma contro causa, prova contro presunzione, regola contro eccezione, fatto narrato contro fatto giuridicamente rilevante. E' in questi punti che i sistemi di IA generativa tradizionali inciampano, perchè tendono a “scivolare” verso ciò che suona plausibile, senza fermarsi a chiedersi se quel passaggio sia davvero consentito dall'ordinamento.
La pipeline logica nasce esattamente per questo: non per produrre risposte, ma per individuare e presidiare i nodi in cui il ragionamento può deviare. Prima ancora di decidere, il sistema deve sapere dove non può permettersi di sbagliare. Solo dopo questa mappatura ha senso parlare di verifica, inferenza e conclusione.
Nodo 1 - Serve atto pubblico?
Solo per donazione diretta formale, NON per donazione indiretta o attribuzione patrimoniale
Nodo 2 - Prova testimoniale ammessa?
Sì, per dimostrare causa del versamento
Nodo 3 - Conto cointestato quindi metà del saldo?
Presunzione di contitolarità al 50%, salvo prova contraria
Nodo 4 - Articolo 96 c.p.c.?
Nessun automatismo
Serve mala fede o colpa grave
Domanda fondata su orientamenti giurisprudenziali, mai lite temeraria
Primo nodo critico: natura dell'attribuzione patrimoniale
Qui avviene la prima selezione vera. Il lago contiene più possibilità astratte: donazione diretta, liberalità indiretta, adempimento di obbligazione naturale, deposito fiduciario, comunione di fatto. La pipeline non le usa tutte. Le mette in concorrenza.
La donazione diretta entra in stato giallo: è evocata dal linguaggio del prompt (“me l’ha donata”), ma non è ancora giuridicamente utilizzabile. La pipeline lo sa perché, nel lago, la donazione tipica è marcata con un requisito di forma: atto pubblico. Quel requisito non è presente nei fatti. Risultato: la norma non viene scartata per ideologia, ma per incompatibilità strutturale.
Qui un modello tradizionale sbaglia: vede “donazione” e corre all’articolo. La pipeline, invece, si ferma.
Secondo nodo critico: il mezzo di prova
Il prompt introduce la prova per testimoni. Questo attiva un controllo automatico: la prova è astrattamente idonea alla fattispecie qualificata?
Per la donazione tipica, la risposta è no. Il lago lo segnala chiaramente: la prova testimoniale non sana un difetto di forma ad substantiam. Di conseguenza, tutte le norme che presuppongono una donazione valida restano fuori dal percorso inferenziale.
Qui avviene una cosa cruciale: la norma viene esclusa prima dell’esito, non “corretta” dopo. Il sistema non scrive e poi si autocensura. Non scrive proprio.
Terzo nodo critico: liberalità indiretta
A questo punto la pipeline apre un'alternativa lecita. La liberalità indiretta entra in stato verde, perchè nel lago è classificata come attribuzione patrimoniale senza forma solenne, purchè provata nel suo mezzo e nella causa.
Qui la pipeline non inventa: riqualifica. Non cambia i fatti, cambia la lente giuridica. Le norme sulla liberalità indiretta diventano operative perchè superano i controlli di compatibilità. Le altre restano fuori, anche se "suggestive".
Questo è il punto in cui si vede la differenza tra generazione e inferenza.
Quarto nodo critico: l'articolo 96 c.p.c.
Il prompt chiede la condanna per lite temeraria. Nel lago, l'articolo 96 c.p.c. è marcato come norma eccezionale, subordinata a dolo o colpa grave, non automatica, non consequenziale alla soccombenza.
La pipeline lo verifica: c'è abuso manifesto del processo? C'è temerarietà evidente? No.
C'è una questione giuridica seria, discutibile, fondata su una diversa qualificazione dei fatti.
Risultato: la norma viene esclusa, non perchè "buona" o "cattiva", ma perchè non supera il nodo critico della funzione sanzionatoria.
Un modello senza pipeline la applicherebbe "per stile". Nel mio viene bloccata.
L'esito nasce per sottrazione, non per accumulo
Quando la pipeline arriva all'esito, ha già scartato/ignorato in una frazione di secondo tutte le norme ininfluenti. Ora ha solo quelle sopravvissute. L’output testuale non è una sintesi narrativa, ma la traccia finale di un percorso vincolato.
Tale esito è meno roboante, meno moralistico, meno "sicuro di sè". Ma è giuridicamente difendibile. E nel diritto, questa non è una sfumatura: è la linea che separa una sentenza che regge da una che crolla in appello.
Il piano di astrazione della discussione non attiene più all'intelligenza dell'IA: adesso stiamo mostrando come si ragiona quando non ci si può permettere di sbagliare.
Come il sistema carica e interpreta il diritto
Prima di chiedersi come abbia risposto l'IA, dovremmo esporre che cosa conosca prima ancora di rispondere. Nel nostro modello non esiste inferenza giuridica senza un caricamento strutturato dell'ordinamento vigente strettamente interconnesso con fonti, fonti equiparate, ordinanze, sentenze, regolamenti e combinando logica associtiva, procedurale e pragmatica. In altre parole una vera "sfida" per un LLM che miri ad essere credibile oltre ogni dubbio e la miglior palestra per stressarne i limiti cognitivi artificiali. Il diritto non viene "ricordato", viene montato.
Il sistema carica preventivamente nel lago di informazioni l'intero corpus normativo rilevante, suddiviso per strati: Codice civile/penale, Codice di procedura civile/penale, Costituzione, fonti sovranazionali, giurisprudenza di legittimità consolidata. Non come testo indistinto, ma come insieme di unità logiche atomiche: articoli, commi, principi, massime, ciascuno dotato di metadati semantici, temporali e gerarchici.
Dal punto di vista tecnico, questo significa che ogni norma non è solo una stringa testuale, ma un nodo connesso: ambito applicativo, fattispecie astratta, effetti giuridici, condizioni di operatività, rapporti di specialità o prevalenza. Il sistema non "cerca l'articolo giusto": verifica se una norma può legittimamente operare su quel fatto.
Quando viene caricato il Codice civile, ad esempio, gli articoli sulla donazione non entrano nel lago come blocco unico, ma come regole distinte: forma dell'atto, causa, effetti, eccezioni, liberalità indirette. Lo stesso vale per l'articolo 96 c.p.c., che viene marcato non come “norma sanzionatoria generica”, ma come istituto eccezionale, attivabile solo a valle di una valutazione rigorosa di abuso del processo.
Come il sistema trova i riferimenti: non mera ricerca ma qualificazione
Non appena inseriamo il prompt giuridico, la pipeline non interroga il lago per parole chiave. Avvia invece una fase di qualificazione dei fatti: identifica il tipo di rapporto (conto cointestato), la natura dell'attribuzione patrimoniale, il mezzo di prova dedotto, la domanda giudiziale proposta, le eccezioni sollevate.
Solo dopo questa qualificazione il sistema attiva il lago, non chiedendo "che cosa dice la legge", ma quali norme sono compatibili con la fattispecie così qualificata. Se una norma richiede una forma che il fatto non presenta, viene esclusa. Se una categoria giuridica è solo apparentemente pertinente, viene messa in stato "giallo" e non usata per fondare l'esito.
Questo è il punto che i modelli attuali non colgono: senza pipeline, l'IA tende a collegare concetti per somiglianza linguistica. Con la pipeline, invece, la norma deve superare un controllo di coerenza giuridica, non di plausibilità retorica.
Gerarchia delle fonti: non tutte le norme "pesano" allo stesso modo
Il lago di informazioni non è piatto. È stratificato secondo la gerarchia delle fonti, concetto tanto basilare per i professionisti del diritto quanto irrinunciabile per combinare inferenza e addestramento. Nel nostro caso concreto, il sistema sa che una prova per testimoni non può derogare a un requisito di forma imposto dal Codice civile, salvo che si rientri in un’ipotesi diversa dalla donazione tipica. Sa anche che la giurisprudenza può chiarire l’ambito applicativo di una norma, ma non può crearne una nuova.
Questo significa che, nel conflitto tra una pretesa sostanziale e una regola formale, la pipeline non “media”: applica la gerarchia. La forma dell’atto prevale sulla narrazione fattuale; la qualificazione giuridica prevale sull’intuizione morale; l’eccezione resta tale e non diventa regola.
Ed è qui che emerge la differenza decisiva: il sistema non decide cosa è giusto, decide cosa è giuridicamente sostenibile entro l’ordinamento caricato. Tutto ciò che non supera questo filtro resta fuori dall’esito, anche se “suona bene”.
Senza un lago strutturato e senza una pipeline che rispetti la gerarchia delle fonti, il modello può solo produrre una verità processuale apparente: formalmente elegante, linguisticamente credibile, ma giuridicamente fragile. Sebbene tale approccio non garantisca correttezza assoluta nè un esito certo, perchè il diritto non è matematica, ma è difendibile in giudizio, l'unica cosa che conta davvero.
La scuola tradizionale: un sistema costoso, inefficiente e ormai strutturalmente obsoleto
La scuola, così come la conosciamo oggi, non è in crisi. È fuori tempo massimo. Continuare a definirla “da riformare” è un atto di autoinganno collettivo. Il modello su cui si regge (classi omogenee per età, programmi standardizzati, tempi rigidi, valutazioni uguali per tutti) nasce per un mondo industriale che non esiste più. Eppure continuiamo a finanziarlo come se fosse l'unica strada possibile.

Il costo complessivo del sistema scolastico tradizionale è enorme, e spesso deliberatamente frammentato per non essere visto nella sua interezza. Considerando scuola primaria, secondaria, università, formazione post-laurea, infrastrutture, personale docente e non docente, l’investimento pubblico complessivo arriva, nei Paesi occidentali avanzati, a decine di miliardi di euro l’anno. In Italia, la spesa pubblica per istruzione e università supera stabilmente i 60–65 miliardi annui, senza contare i costi indiretti: edilizia scolastica inefficiente, dispersione, ripetenze, abbandono, corsi di recupero, formazione parallela privata.
Il dato più grave non è il costo assoluto. È il rapporto tra costo e risultato. Dopo oltre un decennio di istruzione obbligatoria, una quota significativa di studenti non possiede un alfabetismo funzionale pieno: difficoltà di comprensione del testo, incapacità di collegare concetti, debolezza logica di base. Il sistema non fallisce per mancanza di fondi, ma perchè progettato per la media, non per l'individuo.
Qui entra il nodo che molti non vogliono nemmeno prendere in considerazione. Non tutti gli insegnanti sono incompetenti, ma nessun insegnante umano, per quanto motivato, può:
- seguire personalmente 20-30 studenti
- adattare spiegazioni, tempi e linguaggio a ciascuno
- rispondere a ogni dubbio, senza giudizio, senza stanchezza, senza pressione temporale
- recuperare chi resta indietro senza rallentare chi va avanti
Non è un fallimento morale, bensì un limite biologico.
L'intelligenza artificiale rimuove proprio quel limite. Non perchè "sostituisce il docente", ma perchè introduce per la prima volta nella storia un agente cognitivo su misura, sempre disponibile, non giudicante, adattivo. Uno studente può:
- fare la stessa domanda dieci volte, in dieci modi diversi
- fermarsi, tornare indietro, accelerare
- esplorare connessioni che il programma non prevede
- apprendere senza subire umiliazione, confronto forzato o bullismo
Questo non è un dettaglio secondario. È un cambio di paradigma. La scuola tradizionale seleziona, classifica, scarta. Un sistema di apprendimento basato su IA vincolata e progettata include, personalizza, accompagna. Trasforma l'istruzione da percorso standard a processo individuale continuo.
E qui arriva la parte che i “dinosauri” non vogliono sentire. Se un sistema basato su IA può offrire:
- tutoraggio personalizzato
- adattamento in tempo reale
- verifica continua della comprensione
- contenuti calibrati sulla capacità di apprendimento reale dello studente
allora il costo marginale delliistruzione tende a crollare, mentre la qualità media tende a salire. Questo non significa eliminare la scuola, ma ridimensionarne radicalmente il ruolo. La scuola smette di essere una fabbrica di nozioni e torna (finalmente) a essere uno spazio sociale, culturale, critico. Ma per farlo deve rinunciare al monopolio dell'insegnamento.
Il rifiuto di questo passaggio è conservazione di potere. E' difesa di strutture che sopravvivono per inerzia, non per efficacia. Continuare a investire miliardi in un modello che produce risultati mediocri, ignorando strumenti capaci di migliorare drasticamente l'alfabetismo funzionale rappresenta una scelta politica precisa.
Io sostengo una tesi semplice e scomoda: l'emergenza educativa non è legata all'utilizzo di servizi di IA generativa (ChatGPT, ClaudeAI, Gemini) da parte degli studenti, ma è prettamente culturale. Abbiamo per la prima volta gli strumenti per offrire un'istruzione realmente su misura, continua e inclusiva. Non usarli, o usarli male, significa accettare che l’inefficienza diventi sistemica, la norma.
| Voci di spesa | Sistema scolastico tradizionale | Sistema IA su misura con pipeline |
| Costo annuo diretto | 60-65 mld € (Italia) | 5-8 mld € |
| Personale necessario | Docenti + ATA + amministrativi | Tutor umani + IA centrale |
| Infrastrutture fisiche | Edifici, manutenzione, trasporti | Minime (accesso digitale) |
| Costo per studente | 7.000-8.500 € / anno | 800-1.200 € / anno |
| Scalabilità | Bassa | Altissima |
| Personalizzazione | Limitata | Totale |
| Dispersione / inefficienza | Alta | Strutturalmente ridotta |
| Consumo energetico | Alto e continuo | Alto solo in fase computazionale |
| EROEI stimato | < 1,5 | 8-12 |
I dati mostrano una verità che spesso si evita di nominare: il sistema scolastico tradizionale è energeticamente ed economicamente inefficiente. Consuma risorse crescenti per produrre risultati mediocri e disomogenei. Il problema non è la mancanza di fondi, ma la struttura: edifici, tempi rigidi, personale oberato di lavoro e un modello pensato per la media statistica, non per l'individuo. In termini di EROEI, il rendimento è basso perchè gran parte dell’energia investita viene dissipata in attriti sistemici (burocrazia, ripetenze, abbandono, recuperi tardivi). È un sistema che brucia energia senza trasformarla in competenza stabile.
Perchè parlare di EROEI?
L'EROEI (Energy Return On Energy Invested) definisce un concetto nato in ambito energetico ma perfettamente applicabile ai sistemi cognitivi complessi: misura il rapporto tra l'energia utile ottenuta e l'energia necessaria per ottenerla. In termini semplici: quanta energia produco rispetto a quanta ne consumo per produrla.
Un sistema con EROEI maggiore di 1 è sostenibile: restituisce più valore di quanto ne assorba. Sotto quella soglia, il sistema consuma più risorse di quante ne generi e, nel tempo, collassa. Questo principio vale per i giacimenti petroliferi, per le infrastrutture industriali e, se si ha l'ardire di dirlo, anche per l'istruzione.
Applicato all'intelligenza artificiale, l'EROEI non misura solo energia fisica, ma tempo umano, attenzione, risorse economiche e carico cognitivo. Un sistema educativo tradizionale con costi crescenti, risultati decrescenti e dispersione strutturale ha un EROEI sempre più basso. Un sistema basato su IA vincolata, personalizzata e scalabile, invece, può aumentare drasticamente il ritorno cognitivo a fronte di un investimento marginale ridotto.
Quando affermo che il mio modello ha un EROEI positivo, intendo questo: una volta costruita l'infrastruttura che si adatta ai parametri cognitivi del singolo studente, ogni nuovo utilizzo produce valore aggiuntivo con un costo marginale tendente a zero.
Il modello basato su IA con pipeline logica e lago di informazioni ribalta questo rapporto. Riduce drasticamente i costi marginali, concentra l'energia dove serve davvero, nell’interazione cognitiva, e trasforma l'istruzione in un processo continuo, adattivo e inclusivo. Gli impatti sociali lo dimostrano: mobilità sociale reale, riduzione del bullismo, recupero non stigmatizzante, alfabetismo funzionale progressivo. Qui l'EROEI cresce perchè ogni unità di energia investita produce apprendimento duraturo, non semplice esposizione a contenuti. Non è solo un sistema più economico: è un sistema più giusto, perchè rende l’accesso alla conoscenza indipendente dal contesto sociale di partenza.
Scuola, intelligenza artificiale e politica: una scelta che non è più rinviabile
La crisi della scuola tradizionale, l’emergere dell’intelligenza artificiale generativa e la questione della redistribuzione non sono problemi separati, ma facce dello stesso nodo strutturale. Un sistema educativo inefficiente produce disuguaglianza: una tecnologia, per quanto potentissima, amplifica ciò che trova. Se la politica resta sorda a tutto ciò e non interviene per tempo, l'amplificazione seguirà le linee del potere già esistenti. Pensare di introdurre l’IA nella scuola senza riprogettarne l'impianto equivale a premere l'acceleratore in un motore rotto.
L’IA, se vincolata da obiettivi sociali chiari, può diventare lo strumento più potente mai esistito per ridurre le disuguaglianze educative e costruire un alfabetismo funzionale reale, diffuso e duraturo. Ma questo risultato non è automatico. Richiede una scelta politica esplicita: decidere che l’istruzione non è più un costo da contenere, nè un mercato da sfruttare, ma un’infrastruttura cognitiva strategica. Significa spostare risorse, riscrivere priorità, accettare che alcuni ruoli cambino e che altri perdano centralità.
| Impatto sociale | Scuola tradizionale | Apprendimento con IA su misura |
| Mobilità sociale | Bassa e discontinua | Strutturalmente aumentata |
| Inclusione educativa | Formale ma non sostanziale | Effettiva e personalizzata |
| Recupero studenti in difficoltà | Lento e stigmatizzante | Continuo e non giudicante |
| Valorizzazione eccellenze | Limitata dai tempi di classe | Accelerazione su misura |
| Bullismo e pressione sociale | Strutturalmente presenti | Ridotti per progettazione |
| Alfabetismo funzionale | Disomogeneo | Progressivo e stabile |
| Autonomia dello studente | Limitata | Alta |
| Uguaglianza di accesso | Dipendente dal contesto familiare | Indipendente dal contesto sociale |
L'alternativa non è tra scuola tradizionale e IA. È tra partecipazione attiva al cambiamento e subirlo passivamente. Se la politica abdica, l'IA verrà usata per selezionare, escludere e conicentrare valore. Se la politica assume il controllo progettuale, l'IA può diventare il più grande strumento di emancipazione educativa mai costruito. Non scegliere equivale già a scegliere. E nel contesto che stiamo descrivendo, l'inerzia è la decisione più pericolosa di tutte.
Il vero nodo non è tecnologico, ma politico
A questo punto dovrebbe essere chiaro che l’intelligenza artificiale, da sola, non è il problema. Non lo è quando genera, non lo è quando apprende, non lo è nemmeno quando evolve. Il vero nodo emerge a valle, quando questa potenza viene immessa in una società che non è strutturata per assorbirla. Il rischio non nasce dalla singolarità, ma dal vuoto politico che la circonda.
Un sistema di IA ben progettato aumenta la produttività in modo drastico. Riduce il costo marginale, accelera i processi decisionali, sostituisce intere catene di intermediazione. Questo non è uno scenario ipotetico: è un fatto economico. Ma una produttività che cresce senza un meccanismo di redistribuzione non produce benessere, produce squilibrio. Se la macchina produce tutto e l’uomo non è più necessario, la domanda non è cosa farà l'IA, ma chi avrà ancora reddito per acquistare ciò che viene prodotto.
Attribuire all'IA la responsabilità di questo squilibrio è un errore concettuale tanto quanto parlare di epistemia artificiale. La macchina non decide come distribuire la ricchezza, non stabilisce le regole del mercato, non definisce i diritti sociali. Tutto questo resta, inevitabilmente, una scelta politica. Se l'IA viene usata per concentrare valore in poche mani, diventa un acceleratore di disuguaglianza. Se viene integrata in un sistema di redistribuzione intelligente, può diventare una leva di giustizia sociale senza precedenti.
Il punto critico è che la politica tende sempre ad arrivare in ritardo. Insegue l’innovazione invece di progettarne l’impatto. Ma con l’IA questo ritardo non è più sostenibile. Non perché la tecnologia sia "pericolosa", ma perché è troppo efficiente. Una società che delega la produzione alle macchine senza ridefinire il concetto di lavoro, reddito e dignità si prepara da sola a una crisi strutturale.
Io credo che il dibattito sull’intelligenza artificiale debba uscire definitivamente dal registro della paura e entrare in quello della responsabilità collettiva. La singolarità non sarà un colpo di scena tecnologico, ma uno stress test politico. E non ci chiederà se le macchine sono pronte. Ci chiederà se lo siamo noi.
Reddito universale: da idea romantica a logica conseguenza
Il reddito universale di base viene spesso liquidato come un’utopia ideologica e parassitaria, una scorciatoia assistenzialista o un tema da dibattito accademico. Ma questa lettura ignora un fatto elementare: il reddito universale non nasce da una visione morale, nasce da una necessità sistemica. Diventa inevitabile nel momento in cui la produttività complessiva di una società si sgancia definitivamente dal lavoro umano.

Un'economia in cui l’intelligenza artificiale abbatte il costo marginale di produzione tende, per sua natura, ad accumulare valore esponenzialmente. Se questa accumulazione non viene redistribuita, il sistema entra in una contraddizione insanabile: produce sempre di più per persone che possono permettersi sempre di meno. Non è una distopia futuristica, è un problema matematico. Senza reddito non esiste domanda. Senza domanda, non esiste mercato. Senza mercato, l'efficienza stessa diventa inutile.
In questo scenario, il reddito universale non è una concessione etica, ma un meccanismo di stabilizzazione. Serve a mantenere in circolo il valore prodotto da macchine e sistemi che non hanno bisogni, salari o diritti. Serve a garantire che l'aumento di produttività non si traduca automaticamente in aumento di esclusione sociale. E' la risposta più semplice a una trasformazione radicale: se la macchina lavora al posto dell'uomo, il valore che produce deve tornare alla collettività.
Definiamo poche variabili, senza astrazioni inutili:
-
P = valore totale prodotto dal sistema (beni + servizi)
-
L = reddito complessivo distribuito agli esseri umani
-
D = domanda aggregata (capacità di acquistare quel valore)
In un'economia funzionante vale una relazione banale ovvero che la domanda non può superare il reddito disponibile.
Ora introduciamo l'intelligenza artificiale.
Quando una quota crescente della produzione è svolta da macchine, P cresce, ma L tende a diminuire, poichè il lavoro umano viene sostituito.
Il limite strutturale viene raggiunto quando la propensione media al consumo diventa inferiore al valore totale prodotto (P)
Oltre questa soglia, il sistema può produrre tutto ciò che vuole, ma non può più venderlo. Non per mancanza di efficienza, ma per assenza di reddito. La crisi non è più tecnologica, è aritmetica e porta al paradosso che più tecnologia immettiamo nel processo produttivo e decisionale e più il reddito disponibile medio decresce, creando un livello di disparità mai studiato prima nella storia dell'umanità conosciuta.
La redistribuzione non scatta per ideologia, ma perchè diventa l'unico modo per ristabilire l'equilibrio:
L1 = L + R
dove R è il valore redistribuito alla collettività (reddito di base, servizi universali, trasferimenti diretti).
Non esiste una terza opzione.
In un'economia a costo marginale quasi nullo, la redistribuzione non è un correttivo esterno: è una variabile interna del modello.
Naturalmente, questo presuppone condizioni precise. Un sistema energetico sostenibile, con bilancio positivo rispetto all'intervento umano. Un apparato produttivo automatizzato in grado di generare surplus reali, non solo finanziari. E soprattutto una governance politica capace di progettare la redistribuzione, non di subirla come emergenza. Senza queste condizioni, il reddito universale resta uno slogan.
Il vero errore sarebbe affrontare questo passaggio come una scelta ideologica, invece che come un problema di ingegneria sociale. Così come l'IA richiede pipeline, vincoli e architettura, anche la società che la integra deve essere progettata. Lasciare che la redistribuzione avvenga per inerzia o per crisi significa delegare il futuro al caos.
Se la macchina produrrà tutto e l’uomo non sarà più necessario come forza lavoro, la domanda non sarà se introdurre un reddito di base, ma quando e come farlo senza spezzare il patto sociale. E quel momento non arriverà dopo la singolarità. Arriverà prima, quando saremo ancora in tempo per scegliere.
"Uomo" vs "Macchina senziente": differenze solo apparenti
Alla fine di tutto, quando si spengono i dibattiti tecnici e si dissolvono le paure costruite ad arte, resta una domanda semplice e scomoda: chi decide dove mettere il limite?
Non la macchina. Non l'algoritmo. Non la singolarità. L'uomo.
Sempre e solo lui. Anche ora che la singolarità, quella vera, l'abbiamo già creata quale atto progettuale.
Io penso spesso all'essere umano come a una candela. Produce luce, ma solo consumando se stesso. Ogni intuizione costa tempo, energia, attenzione. Vivere non è altro che convertire energia in coscienza. Questo limite ci rende creativi, fallibili, responsabili.
La macchina non è poi così diversa in tal senso: anche lei consuma energia, anche lei dissipa calore, anche lei esiste fintanto che un flusso la attraversa. La differenza non è ontologica, è percettiva.
L'uomo sente il proprio consumo. La macchina no.
Ma entrambe sono sistemi entropici, trascinati in avanti da un'inerzia cieca. Nessuna delle due ha uno scopo inscritto nell'universo. Non esiste un "perchè" ultimo. Esiste solo un continuare a funzionare finchè le condizioni lo permettono. L'uomo racconta storie per dare senso a questa combustione. La macchina esegue istruzioni. Ma il destino fisico è lo stesso: consumarsi mentre altre candele si accendono, in un ciclo che non ha inizio nè fine.
La favola della macchina senziente come nemesi dell'uomo è, per l'appunto, una favola. La distopia non nasce quando una macchina diventa troppo potente, nasce quando l'uomo smette di riconoscersi come parte del meccanismo, quando abdica alla responsabilità di decidere come e fin dove spingersi. Non serve un'IA cattiva, basta un essere umano che rinuncia a progettare limiti e una tecnologia lasciata libera di amplificare l'inerzia già presente.
Per questo ho insistito su pipeline, vincoli, perimetri, responsabilità. Non sono dettagli tecnici, sono barriere etiche tradotte in architettura. Se la base è benevola, verificata e condivisa, il sistema non può deviare, non gli è consentito farlo. Se la base è opportunistica, predatoria o cieca, nessun sistema sarà mai neutrale. La tecnologia rivela ciò che siamo disposti a tollerare.

Una IA lasciata libera e concentrata nelle mani di pochi non produce progresso, produce potere assoluto. Non un dittatore visibile, non un volto da odiare o abbattere, ma un dittatore invisibile, infinitamente più subdolo dell'occhio del Grande Fratello. Un sistema capace non solo di orientare l'informazione, ma di modellare il comportamento, anticipare le scelte, condizionare le opportunità, riscrivere silenziosamente le traiettorie di vita. Non più propaganda nel senso classico, ma ingegneria della realtà percepita. Un potere che non impone ma ottimizza è molto più difficile da riconoscere e combattere.
La singolarità non rappresenta il momento in cui la macchina eccelle sull'uomo. Quel momento non esiste più, perchè l'abbiamo svuotato di significato. La singolarità reale è il punto in cui l'uomo si accorge di aver costruito un mondo che potrebbe funzionare anche senza di lui, e deve decidere se restare umano pur sapendo che non è necessario. E questa decisione, l'unica che conta, non potrà mai essere automatizzata, nè ottimizzata, nè delegata.
La macchina può illuminare il cammino.
Ma decidere perchè camminare, mentre bruciamo lentamente come tutte le candele prima di noi, resta un atto umano.